所以,音频压缩技术在通讯和多声道伴音领域里受到高度重视。
音频数据压缩粗分为波形压缩、分析合成和混合压缩三类。
一、 波形频谱压缩编码法
原理是依据人类的听觉心理,从原始取样数据中压缩掉冗余的成分,即去掉听不到的频率分量,还原后的声音基本上保持原样。由于这种压缩的保真度高,目前AV系统中的音频压缩都采取这类方案。附表是已在采用的这类压缩的要点。
附表所列的数据率为典型数据率,放音质量能满足要求,基本上与CD音质相当,也有低于表列数据率的格式,但对音质有影响。
每个声道一秒钟声音数据在64kbit以上,数据量仍旧是太大了点。若录立体声音乐74分钟,载体存储空间要56Mbit,以IC固态存储器现阶段的价格,还是贵了。将芯片做成固态录音机,由于省去了磁光机械,整体价格还可能被民用接受。若单独做成IC唱片就太离谱了。
二、 分析合成编码法
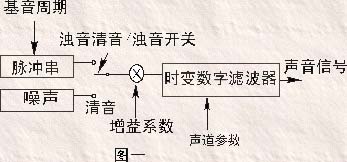
这种方法是在分析发音机理的基础上用电学模型和电气参数来模拟发音器官,从而使需要的数据量很少,压缩率非常高。分析时从语音中提取共振峰、声道参数等声音信息。还原时,也用这些参数及电模型来模拟出波形。压缩率在1.2kbps~9.6kbps之间。
国内用得较多的是LPC线性预测编码方式,原理见图一。
《银屏笙歌》印象
声音被模拟成声源和声道两个部分构成。声源为噪声和脉冲两种,声道相当于一个滤波器,气管口腔形状不同相当于声道滤波器的参数不同,最后就生成不同声音。
分析合成方法数据量小,但计算量很大。由于声音从发声模型出发,不是从波形出发仿真,保真难度大,目前的保真度还很差。例如,某人说了一句话,分析出参数再由参数合成的声音,能听出这段话的字句就合格了,听起来不是机器语言,即自然度好一些已相当不错了,要能听出谁在说话就不容易。现在的应用还停留在语音的传送和合成上,不少电话局声讯台给出的就是这种声音。
要用于消费类音频产品还要走一段路,但前景非常好,现在语音水平上的固态录音机已进入民用领域。




